
type
status
date
slug
summary
tags
category
icon
password
原始链接
- GitHub 仓库:lupantech/AgentFlow
- 论文页:arXiv:2510.05592
- ICLR 2026 展示材料:Slides
- 模型与演示:Hugging Face Model、Demo
为什么今天选它
今天看下来,几个候选都值得关注:browser-use 更偏“让 coding agent 有可用浏览器”;Microsoft Agent Framework 是生产框架,但《智汇AI》最近已经写过;Agent Lightning 解决“现有 agent 怎么接强化学习训练”,思路很重要,但发布时间更早。
我最后选 AgentFlow,因为它打中的问题更靠近 agent 的下一步:不是再包一层工作流,也不是只把工具接得更多,而是问一个更硬的问题:多轮 agent 在真实执行过程中,能不能学会更好的规划和工具使用方式?
它的项目页标注为 ICLR 2026 Oral,论文作者来自 Stanford、Texas A&M、UC San Diego 和 Lambda。仓库今天查到约 1.9k stars、227 forks。热度不是最大,但研究问题足够集中,也有代码、模型、演示和配图,适合拆开看。
它解决的不是“有没有 agent”,而是“agent 怎么变好”
常见 agent 做法是固定一个 loop:模型读任务,拆步骤,选工具,执行,观察结果,再继续。这个 loop 可以跑起来,但多数系统只靠提示词、手写规则或人工调参来改善。失败时,我们常看到两类问题:
- 规划器重复走错路,明明工具报错了,下一轮还用类似方式重试。
- 工具越接越多,但模型并不知道什么时候该用哪个工具,什么时候应该停。
AgentFlow 的切入点是:把 agent 的多轮执行过程当成可以训练的过程,尤其训练其中最关键的 Planner。论文把它叫做 in-the-flow,意思是训练发生在真实多轮交互里,而不是先离线造一批静态样本,再希望 agent 上线后自然泛化。
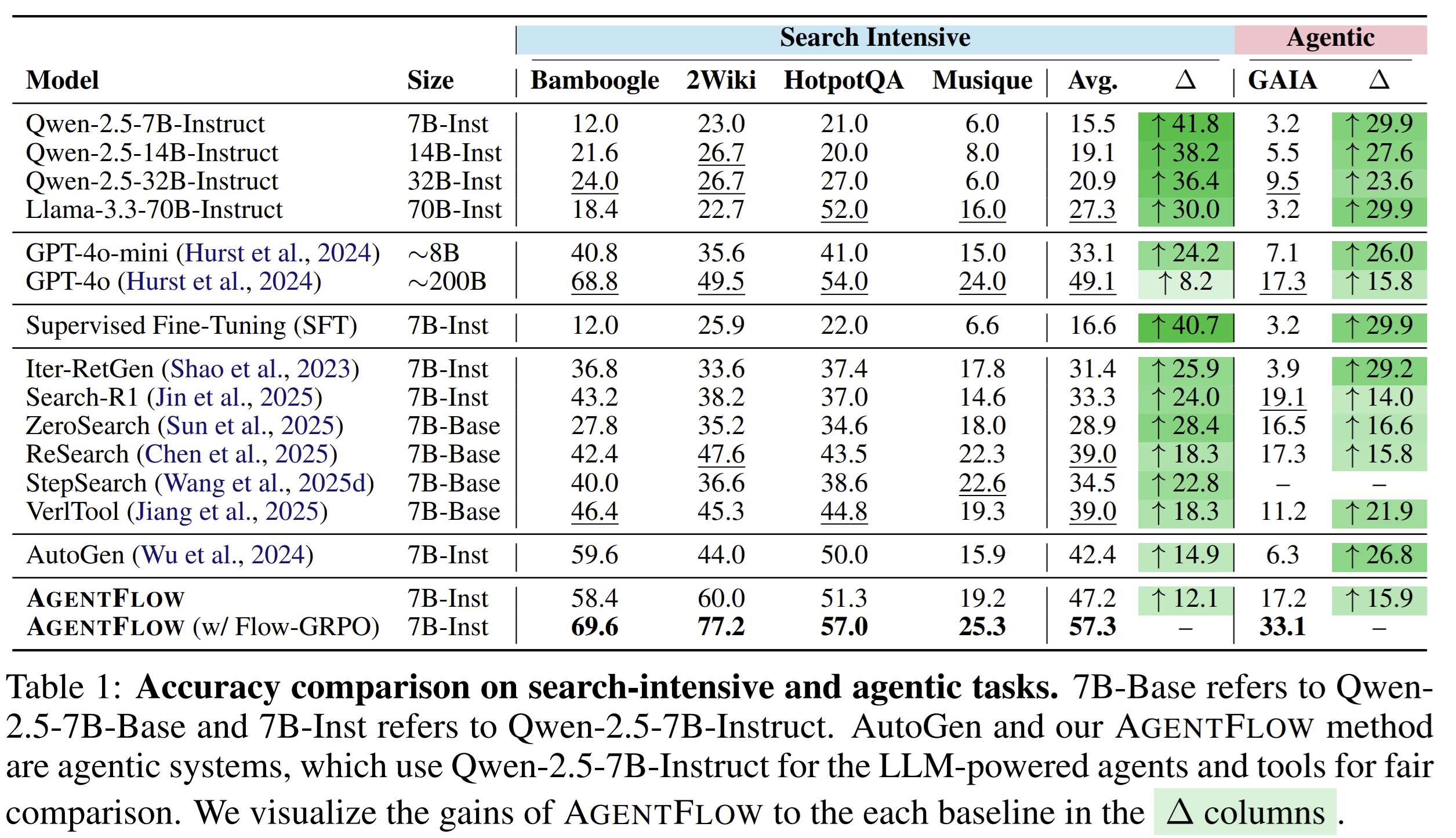
图源:AgentFlow GitHub assets/maintable1.png。这张表对应搜索类和 agentic 任务。作者用 Bamboogle、2Wiki、HotpotQA、Musique、GAIA 等任务比较 AgentFlow、AutoGen、Search-R1、GPT-4o 等方法。项目页给出的总结果是:7B 规模 AgentFlow 在十个 benchmark 上,相比强基线平均提升搜索 14.9%、agentic 14.0%、数学 14.5%、科学 4.1%。这里真正值得看的是它不是单一工具题,而是跨搜索、数学、科学、GAIA 这类长链任务一起测。
系统怎么跑:四个模块,一个共享记忆
AgentFlow 把系统拆成四个角色:Planner、Executor、Verifier、Generator。
Planner 负责读任务、看当前记忆、选工具、定当前子目标。Executor 负责把 Planner 的动作变成实际工具调用。Verifier 判断这轮结果能不能推进任务,如果不能,就把失败原因写回记忆。Generator 在最后根据累积记忆产出答案。
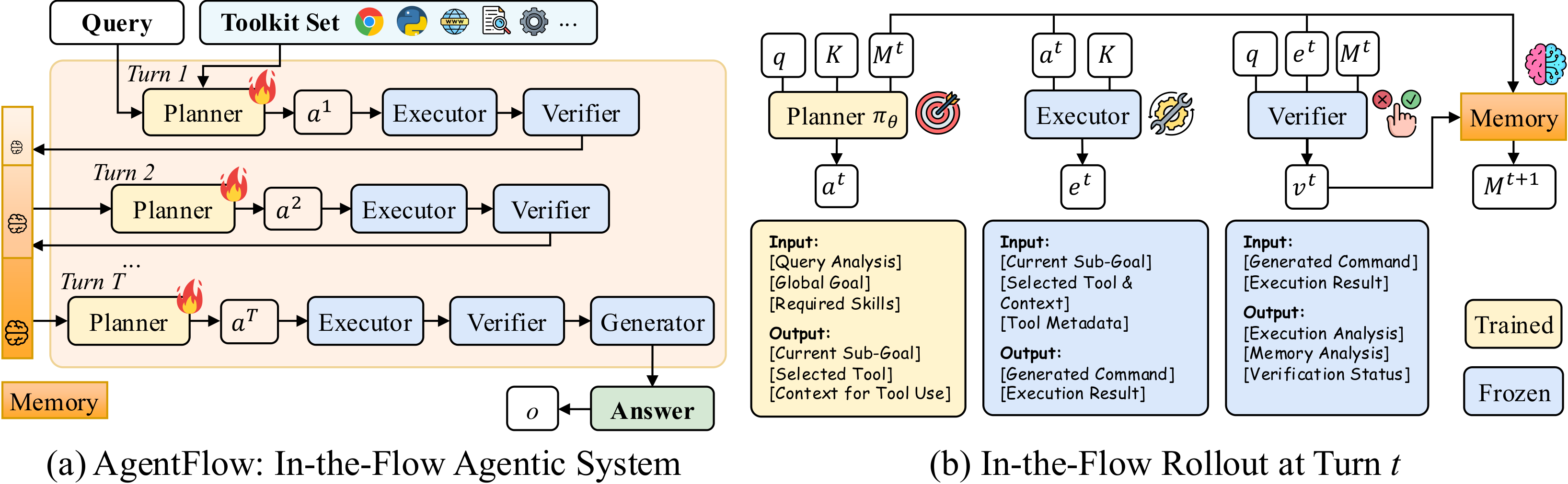
图源:AgentFlow GitHub assets/framework.png。左边是完整 loop:同一个任务会经历多轮 Planner -> Executor -> Verifier,直到结束或达到轮数上限。右边是单轮状态变化:输入包括问题、工具集合和当前记忆;输出包括子目标、工具选择、执行结果、验证状态,最后更新记忆。
这套拆法本身不新。AutoGen、CrewAI、MetaGPT 这类系统早就有多角色、多模块、工具调用。AgentFlow 的关键不在“四个模块”的命名,而在它只训练 Planner。Executor、Verifier、Generator 更像固定环境,Planner 在这个环境里学习怎样拆目标、选工具、利用已有记忆。这比训练一个巨大的“全能 agent 模型”更克制,也更接近实际产品里的瓶颈。
真正的新点:在多轮 loop 里训练 Planner
AgentFlow 用 Flow-GRPO 来训练 Planner。它不是让模型一次性输出完整答案,也不是把所有思考和工具调用拼成一条长序列去训练。它会对同一个问题采样多条完整轨迹,看哪条最后答对,然后把这个最终结果反向分配到每一轮 Planner 的决策上。
说得直白一点:如果最终答对了,系统会把这条路径里的每一次规划选择都当作可学习信号;如果最终失败,也能让 Planner 看到哪些选择更可能把任务带进死路。
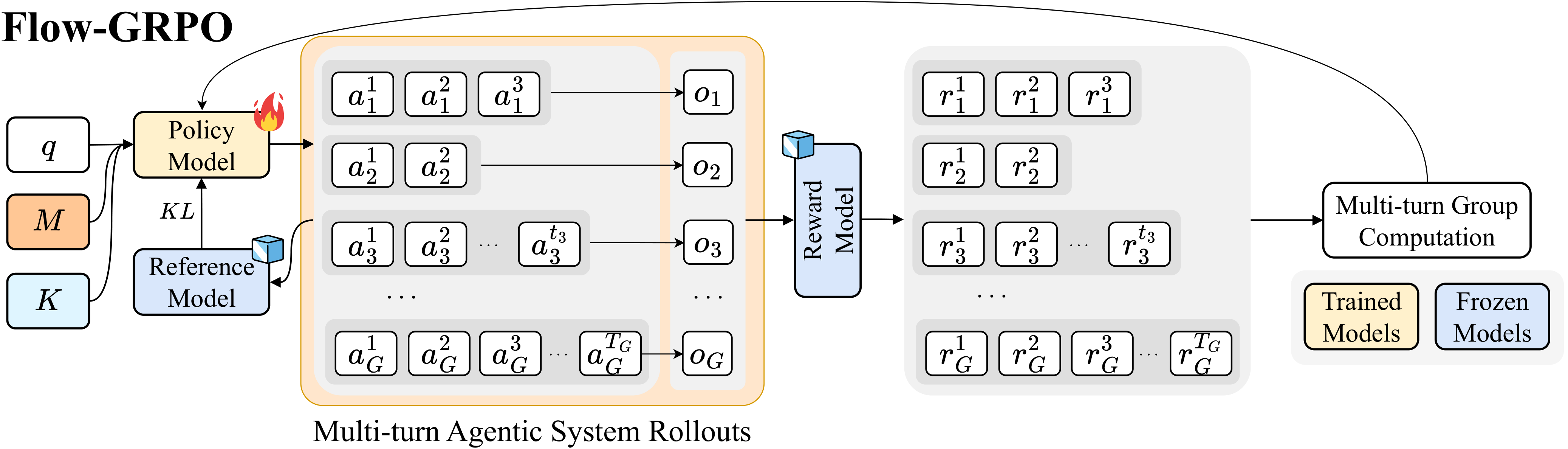
图源:AgentFlow GitHub assets/flow_grpo.png。这张图展示的是训练层:同一个问题会产生一组多轮 rollout,每条轨迹得到最终结果,奖励模型给出反馈,再用组内比较来更新 Planner。蓝色模块是冻结部分,黄色模块是训练部分。
这个设计绕开了长链 agent 训练里最麻烦的一个点:最后答错,到底是哪一步错?传统做法要么只看最终答案,要么试图给每一步写细粒度奖励。前者太粗,后者难写且容易把系统带偏。AgentFlow 选择了折中方案:用最终结果作为全局信号,再通过同组轨迹比较降低波动。
工具调用不是越多越好,关键是用得准
AgentFlow 的一组分析很有价值:训练后,Planner 的工具选择分布变了。比如在 2Wiki 这种广泛知识检索任务上,Google Search 的占比明显上升;在 MedQA 这类医学任务上,Wikipedia Search 和 Web Search 的比例更高。右侧图还显示,多项任务里的工具调用错误率下降。
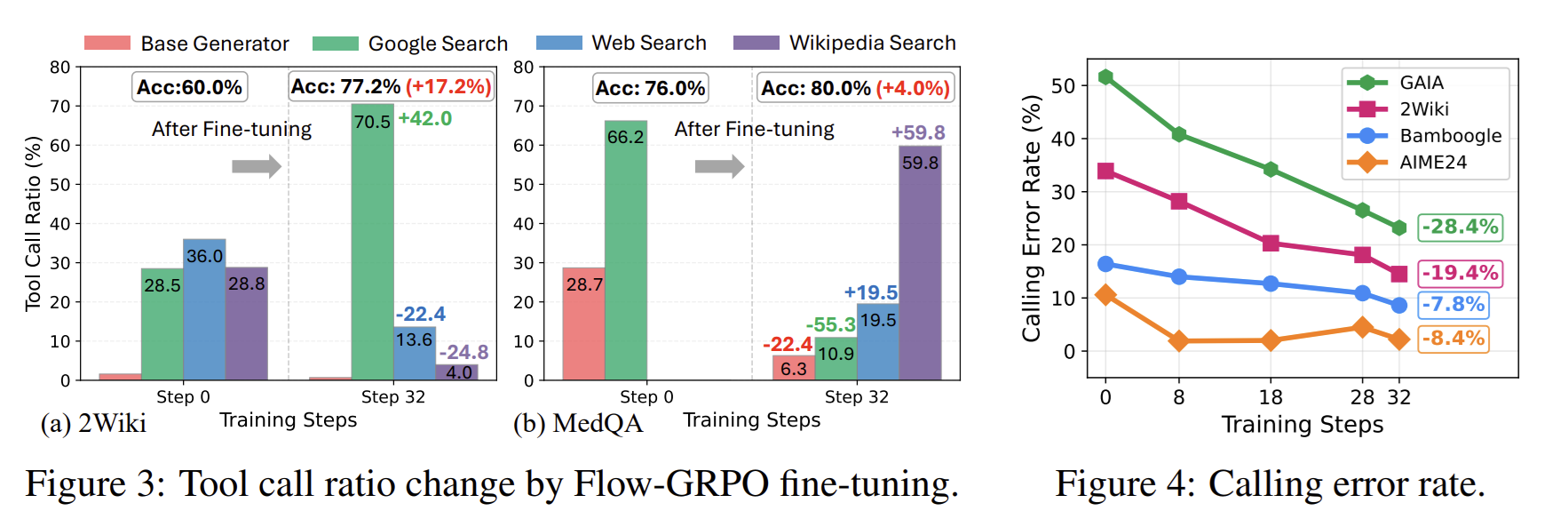
图源:AgentFlow GitHub assets/tool_call.png。这张图比最终准确率更值得产品团队看。很多 agent 失败不是因为模型完全不会推理,而是它把工具当成“能用就用”的按钮。真正要优化的是:该查网页时别写代码,该用专业搜索时别泛搜,该停时别继续绕圈。
这也解释了为什么 AgentFlow 强调 Planner。工具层可以不断升级,但如果上层规划器不会根据任务类型、历史失败和工具反馈调整动作,更强的工具也会被浪费。
和常见 agent 设计相比,它新在哪里
第一,AgentFlow 不是普通 workflow 包装。普通 workflow 的进步主要来自“把步骤写清楚”。AgentFlow 关心的是这些步骤能不能从执行结果中学习。
第二,它也不是单模型 ReAct 的简单升级。ReAct 把推理和行动交织在一条模型输出里,直观、好用,但长任务里容易出现上下文膨胀、重复试错和工具误用。AgentFlow 把规划、执行、验证、生成拆开,让 Planner 的训练目标更清楚。
第三,它和 Agent Lightning 这类框架无关训练思路有相通点:都想让 agent 轨迹变成训练数据。区别在于 AgentFlow 更像一个具体 agentic system:它把系统结构、记忆更新、工具集合、Planner 训练放在同一个闭环里验证。Agent Lightning 更偏“给已有 agent 接训练管线”,AgentFlow 更偏“设计一个可被训练的 agent loop”。
哪些地方只是工程包装?四个模块、共享 memory、工具集合、Verifier 这些概念本身并不新。项目 README 里的 quick start、环境变量、工具测试也只是开源工程正常配置。真正有含金量的是:它把可训练边界放在 Planner,并用在线多轮轨迹训练来证明这个边界有效。
可复用的方法论
对产品和研发更有启发的,不是照搬 AgentFlow,而是下面几条:
- 先找到 agent 的瓶颈模块。很多产品的问题不在模型不够大,而在 Planner 或 Router 不会做选择。
- 每一次工具调用都要留下结构化轨迹:当前目标、选择的工具、输入、输出、验证结果、记忆变化。没有这些记录,就谈不上训练和复盘。
- Verifier 不只是“检查答案”,也应该决定记忆怎么更新。否则 memory 很容易存进错误中间结论。
- 评测不能只看最终答对率。还要看工具调用错误率、重复调用、无效重试、平均轮数和停止质量。
- 轮数上限是产品参数。给 agent 更多轮不一定更好,必须配合验证器和停止条件,否则只是更贵的重复试错。
风险和没被证明的地方
AgentFlow 的实验很强,但还不能直接说明它已经适合真实业务落地。
第一,奖励依赖最终答案和 LLM-as-judge。这个设置方便做大规模实验,但真实业务里很多任务没有标准答案,判错成本也更高。
第二,记忆更新看起来干净,但实际产品里的 memory 会遇到脏数据、旧信息、用户偏好变化、权限边界。论文没有重点处理这些问题。
第三,工具环境相对可控。真实企业系统里的工具会有权限、延迟、失败重试、副作用和审计要求。AgentFlow 主要证明规划和工具选择能被训练,还没有覆盖完整治理问题。
第四,它只训练 Planner,短期看很务实,长期看也可能成为限制。如果 Executor 或 Verifier 本身不稳定,Planner 可能学到的是绕过问题,而不是系统整体变好。
第五,结果集中在研究 benchmark。GAIA、HotpotQA、AIME、MedQA 这些任务有代表性,但和真实工作流仍有距离:真实任务常常目标模糊、反馈延迟、需要人确认,还会涉及隐私和安全。
今日沉淀
- agent 的核心能力,经常卡在 Planner,不是卡在工具数量。
- 工具调用要能被记录、比较、训练;否则只是提示词工程。
- memory 不是仓库,必须有验证门槛。
- 多轮 loop 的价值在于纠错,不在于无限延长。
- 评测 agent 时,要问它是否用了正确工具,而不只是最后有没有答对。