
type
status
date
slug
summary
tags
category
icon
password
原始链接
- 论文 HTML:arXiv HTML
- 论文 PDF:arXiv PDF
- Hugging Face 论文页:Code as Agent Harness
为什么今天选它
今天我比较了几个候选:
earendil-works/pi、Natural-Language Agent Harnesses、Agentic Harness Engineering 和 Code as Agent Harness。Pi 更像一个正在变热的开源 coding agent 产品,GitHub 页面显示约 66.9k stars,并把自己定义成可自定义的 agent harness;它很适合作为工程案例。
Natural-Language Agent Harnesses 把 harness 写成可执行的自然语言文档,想法新,但范围更窄。Agentic Harness Engineering 更偏实验系统,重点是让 agent 根据轨迹自动改自己的 harness,实验结果具体,但讨论对象主要是 coding agent。我最后选
Code as Agent Harness,主要因为它把这几条线放到了一张图里。论文 2026 年 5 月 18 日提交,Hugging Face 标为 #1 Paper of the day,有 223 个 upvote;配套 GitHub 资料库有 531 左右 star,并且整理了三层框架和大量相关论文。它不是在介绍一个新工具,而是在追问一个更底层的问题:为什么现在的 agent 不再只是“模型加工具”,而是越来越像一个围绕代码、状态、执行反馈和协作流程搭起来的运行系统。它要解决的问题
过去讲 AI Agent,经常会拆成模型、工具调用、记忆、计划、反思、评测几个模块。这个拆法有用,但它漏掉了运行时最麻烦的一层:这些模块真正跑起来时,总要落到某种可执行、可检查、可回滚的东西上。对 coding agent、GUI agent、科学发现 agent、机器人 agent 来说,这个东西经常就是代码。
论文的核心判断是:代码不再只是 agent 最后生成的结果。代码正在变成 agent 的操作介质。agent 用代码表达中间推理,用代码调用工具,用代码建模环境,用测试和执行结果验证自己,用仓库、日志和工作流保存状态,多 agent 还会围绕同一份代码做分工、审查和修复。

这张图最值得看的不是分类有多全,而是它把 agent 的“想”和“做”放到同一个闭环里:左边是 agent 生成代码,右边是外部环境执行并返回验证信号,中间的 harness infrastructure 负责把推理、动作、环境状态、记忆、调试和多人协作串起来。harness 不是提示词外壳,它更像 agent 能不能长期工作的运行层。
核心思想:代码是可执行的上下文
论文把 code as agent harness 分成三层。
第一层是 harness interface。代码把模型输出变成可执行、可检查的结构。数学推理里,代码可以把中间计算交给解释器或求解器;GUI/OS agent 里,代码可以变成 DOM 操作、系统命令或 API 调用;在软件工程里,代码库、测试、日志和执行轨迹本身就是环境状态。
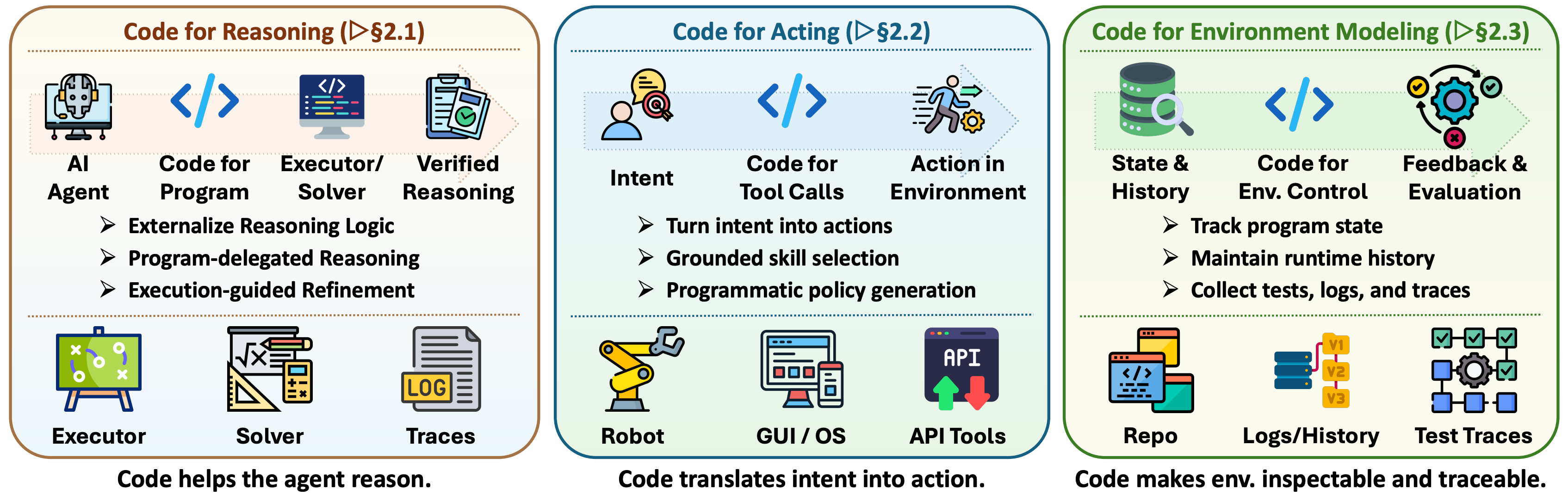
这张图说明了一个容易被忽略的点:工具调用并不是“模型想做什么就调哪个函数”。可靠的 agent 要先把意图翻译成动作,再通过环境反馈确认动作有没有生效。代码在这里的价值,是把意图变成可执行对象,也把反馈变成可检查证据。
第二层是 harness mechanisms。这里包括 planning、memory、tool use、feedback control 和 harness optimization。论文对 tool use 的表述很关键:工具不是附加能力,而是模型意图和外部系统之间的治理接口。一个可靠的 harness 要决定哪些工具可用、schema 怎么暴露、权限怎么给、执行在哪里发生、结果怎么清洗或压缩、哪些危险动作要人类确认。
memory 也不是简单的“向量库记忆”。在 code-as-harness 视角下,memory 是状态管理:哪些信息留在当前上下文,哪些被压缩,哪些写入外部存储,哪些变成可复用技能、测试、脚本或仓库状态。对长任务来说,这比“记得更多”更重要。agent 真正需要的是在正确时刻拿到正确状态。
第三层是 scaling the harness。单个 agent 可以靠对话推进任务,多 agent 就必须有共享状态,否则很快变成角色扮演。论文指出,代码的优势在于它可以执行,可以产生非语言的客观信号。多 agent 系统里的收敛,不应该只靠“大家同意了”,更应该靠测试通过、行为一致、审查完成、状态冲突解决。
它和常见 agent 设计有什么不同
常见 agent 设计往往从 loop 开始:plan -> act -> observe -> reflect。这个模型直观,但有一个缺口:每一步留下来的东西是什么?如果只是聊天记录,系统很难复用、审计和纠错。
Code as Agent Harness 的新意在于,它把“留下来的东西”摆到中心位置。测试、脚本、工具封装、执行轨迹、环境模型、技能库、仓库状态、工作流配置,都不是附属产物,而是 agent 系统的主干。这样一来,agent 的能力就不只取决于模型单轮回答,而取决于它能不能不断生产、执行、观察、修改这些可检查的中间对象。这里也有一些只是工程包装的地方。比如把 planning、memory、tool use 重新归类,本身并不新;很多 coding agent 和自动化平台早就在做。论文的价值不在于发明这些模块,而在于给它们一个更统一的解释:凡是能让 agent 长期运行、保存状态、接受反馈、支持协作和验证的代码对象,都应该被看成 harness 的一部分。
对产品和研发的启发
第一,别只优化 prompt。很多 agent 失败不是因为模型不会想,而是环境接口、权限边界、状态保存、错误反馈和验证方式太粗。把工具、执行日志、测试、失败样本和人工审批设计好,往往比多加几句系统提示更有效。
第二,把中间产物产品化。一个 agent 做完任务后,如果只给最终答案,价值会很薄。更好的形态是留下可复用脚本、测试用例、操作记录、决策说明、可回滚变更和失败原因。用户下次不是从零开始,而是在一套已经积累过的 harness 上继续。
第三,评测要看过程。只看最后任务成功率,会掩盖很多问题:agent 是否用了危险工具,是否绕过权限,是否靠偶然通过测试,是否留下不可维护状态,是否在多 agent 协作中产生冲突。论文提到的 open problems 里,evaluation beyond final success 是我认为最实际的一条。
第四,人类介入要变成状态,而不是临时打断。危险操作、权限申请、审查意见、回滚选择,都应该进入系统状态,供后续 agent 读取和遵守。否则 human-in-the-loop 只是一个弹窗,不是治理机制。
风险和还没验证的问题
最大风险是把“代码可执行”误解成“代码就可靠”。执行反馈很有用,但反馈经常是不完整的:测试可能覆盖不足,环境可能有隐藏状态,GUI 操作可能成功但语义错误,机器人仿真可能过不了现实世界。论文也把 incomplete feedback 下的 verification 列为开放问题。
第二个风险是共享状态会变成新的混乱源。多 agent 都能改仓库、记忆、工具和工作流时,冲突不只是文本冲突,还包括语义冲突、权限冲突和版本回退。没有事务、审计和回滚机制,多 agent 很容易把问题扩大。
第三个风险是自我优化可能带来回归。像
Agentic Harness Engineering 这类方向已经在尝试让 agent 自动改 harness,但如果没有足够好的对照、预测和回滚,系统可能在某个 benchmark 上变好,同时破坏真实任务里的稳定表现。第四个问题是成本。代码作为 harness 往往意味着更多执行、更长日志、更复杂的状态管理和更多验证。对产品来说,最后要算的是 cost per completed task,而不是 token 单价。

这张应用图提醒我们,code-as-harness 不只是 coding agent 的话题。GUI agent 需要把界面变成可观察状态,科学发现 agent 需要把假设、实验、数据分析串成程序世界,机器人 agent 需要把技能写成可复用、可验证的控制代码。场景不同,但共同点很清楚:真正有用的 agent 都需要一个能承载状态和反馈的执行层。
今日沉淀
- Agent 的核心不只是 loop,而是 loop 里留下了什么可执行、可检查、可复用的东西。
- Memory 更像状态管理,不只是把历史塞进向量库。
- Tool use 是治理接口,权限、执行位置、结果清洗和人工确认都要设计。
- 多 agent 协作不能只靠角色分工,要有共享状态、客观验证和冲突处理。
- 评测不能只看最终成功率,还要看过程是否安全、可审计、可回滚。